这是Ceph开发每周谈的第九十七篇文章,记录从17年10月24号到17年10月30号的社区开发情况。笔者从前年开始做Ceph的技术模块分析到今年中告一段落,想必有挺多人期待下一篇Ceph技术分析。考虑到Ceph的发展已经从前年的一穷二白到现在的如火如荼,但对于社区的方向和实况仍有所脱节,笔者考虑开始Ceph开发每周谈这个系列。每篇文章都会综述上周技术更新,围绕几个热点进行深度解析,如果正好有产业届新闻的话就进行解读,最后有读者反馈问题的话并且值得一聊的话,就附上答疑部分。
-
一句话消息
无
-
PebblesDB
Pebbles 是一个面向写优化的键值数据库,类似于 RocksDB 但极大的增大了写带宽和减少写放大,同时带来了10-30% 在小范围查询的负担,在 SOSP 17 发表了关于 PebblesDB 的文章(http://www.cs.utexas.edu/~vijay/papers/sosp17-pebblesdb.pdf)。同时,PebblesDB 也在 Github(https://github.com/utsaslab/pebblesdb) 上开源。
RocksDB 是基于 LSM 设计的流行数据库引擎,在整体 API 特性、稳定性以及性能的权衡上可谓是现代键值数据库的一流水平。往往主要被诟病的是写放大带来的性能损耗,在某些情况下,高达 42X 的写放大实在是难以忍受。
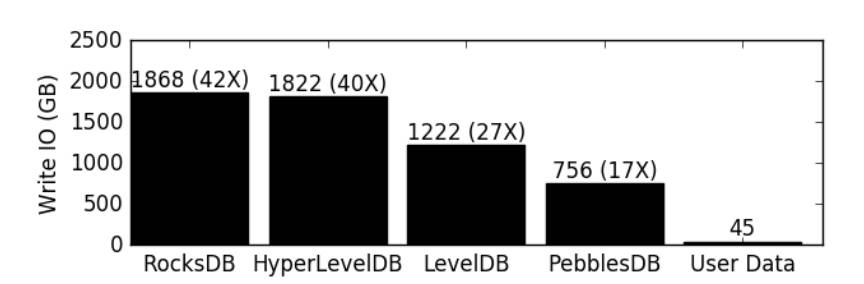
本身 LSM 设计带来的诸多优势以及各个场景下的性能也不能失去,这使得 PebblesDB 团队思考 RocksDB 上的哪些设计可以优化。他们找到了 LSM 结构中多层 SST 文件强制保序这个约束,这个约束是指在 Level 大于 0 的层次中,每一层的 SST 文件都互相没有键范围交叉,这使得在读取和范围查询上有较好的优势。但这个无键值交叉的约束给 Compaction 带来的极大的负担,通常来说,如果每一层都只有一份数据且每次往下一层写只写一次,会大大降低写放大问题。因此 PebblesDB 砍掉了这个约束,缩小 SST 文件的大小,使用 Skiplist 结构来进行同一个层的 SST 组织。这个数据结构成为 FLSM(Fragmented Log Structured Merge Tree),本质上是在类似于数据结构中的顺序队列,RocksDB 采用 Compaction 来不断重写来重排顺序,而 FLSM 雇佣了 Skiplist 来进行组织,使得在同一层的 SST 排序只需要重写 Skiplist 内部,而不需要重写实际的值。
这个 Skiplist 称为 Guard,每个 Guard 在每个层次负责一部分 KeySpace,而每次往下层次都需要从上级 Guard 分裂出,因此如何选择 Guard 变得非常重要,论文中也提到了 Guard 的选择策略。

以下列出了 PebblesDB 在不同场景跟其他 LSM DB 比较的情况,可以看到在大部分场景下都有显著优势。
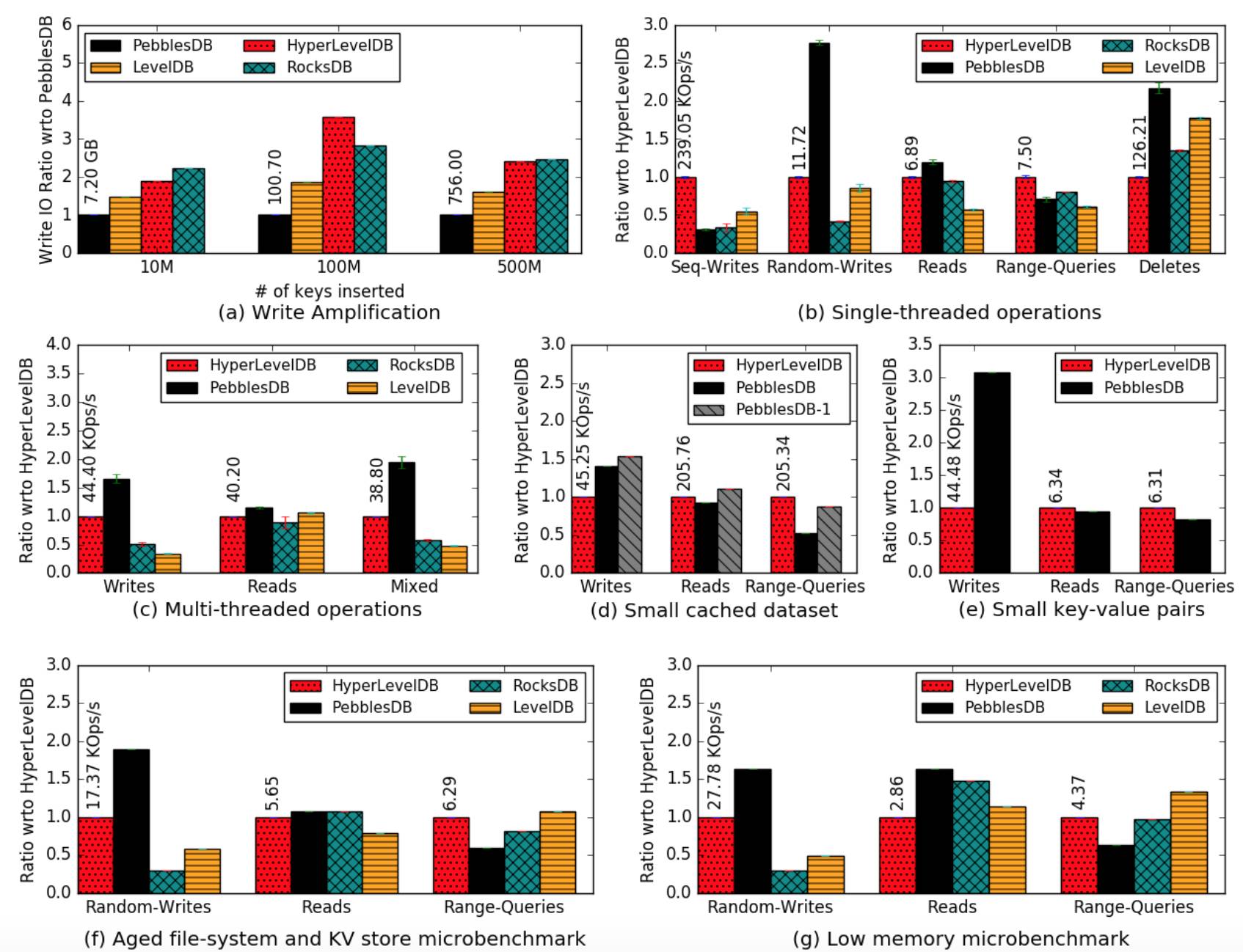
RocksDB 拥有广泛的生态,如果 PebblesDB 能够拥有 RocksDB 完整的 API 语意,同时只在某些场景下性能降低但是大幅度增加基础性能,相信会有很好的应用场景。关键是 PebblesDB 在选择如何优化 RocksDB 点上非常精细,抓住了 Write Amplication 里不同类型 Rewrite 的主要矛盾,以索引替代方式进行了实现替换,令人耳目一新。相比去年 FAST 中键值分离设计更加简单,效果易评估。因为做的修改比较局部。