编者按:本文系XSKY资深软件定义存储专家王志强先生,结合日前他参加在美国举行的全球顶级闪存峰会“FMS 2018”经历,对存储介质的发展的洞察。FLASH MEMORY SUMMIT FMS是目前存储业内国际性的顶级闪存峰会,在美国硅谷加州圣克拉拉会议中心举办,主要展示全球过往一年存储行业最为领先的技术以及共同探讨下一代存储技术发展,每年都吸引了来自全球存储届精英和高端行业领导企业。FMS 2018上,海力士,三星,东芝,希捷、西部数据,Intel,Marvell等闪存领导企业悉数参加。

「NAND」
为了降低成本,增大密度,NAND Flash朝着两个方向在发展。一个是在一个cell上存储更多的bits,另一个则是从平面发展到3D。从最初一个cell上存储一个bit的SLC,发展到两个bits的MLC,再到三个bits的TLC,到了今年,终于进展到在一个cell上存四个bits的QLC。美光和Intel分别在今年的会议上推出了自家的QLC产品。美光的型号是5210 ION系列,Intel的是D5系列,譬如已经被腾讯采用的达到8T容量的D5-P4320。由于Intel和美光是联合开发,从技术上来讲这两个系列应该差不多。同时,Intel还发布了第一款消费级的QLC NAND SSD 660p,512GB的只卖99刀。相比起TLC来说,QLC可以降低25%-30%的成本,其价格甚至比10TB的HDD还要便宜,因此厂商们的目标都是奔着替换HDD来的。美光的数据显示其一块8TB的5210 QLC SSD跑Cassandra的IOPS性能是4块2.4TB 10K HDD的4倍。而由24块该SSD组成的3节点Ceph集群的读性能可以达到70Gb/s。Intel则表示腾讯在他们的CDN环境中部署了D5-P4320后,服务的客户数增长了10倍,同时服务的QOS增长了3倍。
相比起这些优点,QLC也有自己的一些缺点不容忽视。一般来说,QLC的可擦除次数只有1K次,就算每天只写一次的话,也只能使用3年不到。而对于TLC来说,这个值一般是3K,SLC则可以达到10K。QLC的耐用度还需技术进一步发展。同时,由于QLC一般都是高密度盘,其对于整个FTL的设计,譬如地址映射,磨损均衡等也提出了一些难点。还有就是QLC SSD一般是针对读密集型业务,如果业务中有比较多的写,其性能下降会比较大。
另一方面,NAND Flash最开始是平面铺展,随着2D平面闪存工艺进步,到达15nm的水平后,平面结构的NAND闪存已接近其实际扩展极限。于是研究人员就尝试往上扩展,采用3D的架构。去年各厂商纷纷推出64层的设计,而到了今年,已经发展到96层了,采用3D架构的Flash也成为了标准。根据发展线路图,明后年应该是会推出128/256层的设计了。
「Persistent Memory」
除了朝低成本大容量发展之外,存储介质也在不断的向高性能进军。从下图可以看出,目前主流的DRAM的时延可以做到10-100ns级别,NAND SLC/TLC的时延在几十到几百个us之间,其余各种介质则尝试填上这中间的空白。其中3D XPoint SSD已经推出,并在市场上得到了广泛应用,3D XPoint的DIMM形态也会马上面市,作为Persistent Memory的一种主流形态存在。其他像MRAM,ReRAM由于各种各样的原因暂时还得不到广泛应用。
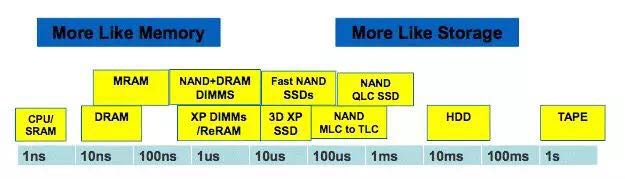
说到PM (Persistent Memory),这也是FMS上的一个热点议题。它的定义是非易失性内存,包括PCM, ReRAM, MRAM, NVRAM等,采用字节寻址的方式访问。目前已经出货的PM主要是NVDIMM-N类型,一种采用DRAM和SLC NAND混合的方式来存取数据。数据先是走DIMM接口存到DRAM,然后会定期的刷到NAND上。当发生掉电的时候,其上面的电容也可以保证将DRAM中的数据刷到NAND里。这种NVDIMM-N容量不会太大,一般是16GB的DRAM加32GB的NAND。未来随着Optane,MRAM,ReRAM,ZNAND等的进步和面市,以及各种混合产品的推出,用户将有机会体验到多种不同价格/性能/特性的PM,并由此带动相应架构的兴起。
「NVMe & NVMe-oF」
NVMe协议从诞生之初,由于其低延迟高并发的特性,就一直是各种技术讨论交流的热点。其标准由NVM express组织在制定,最新的版本是17年发布的1.3版,增加了Streams,Sanitize,Virtualization,Self-test等功能。目前正在制定1.4版的标准,预计会加入IO Determinism, Persistent Memory region, Asynchronous Namespace Access, Multipath等功能。
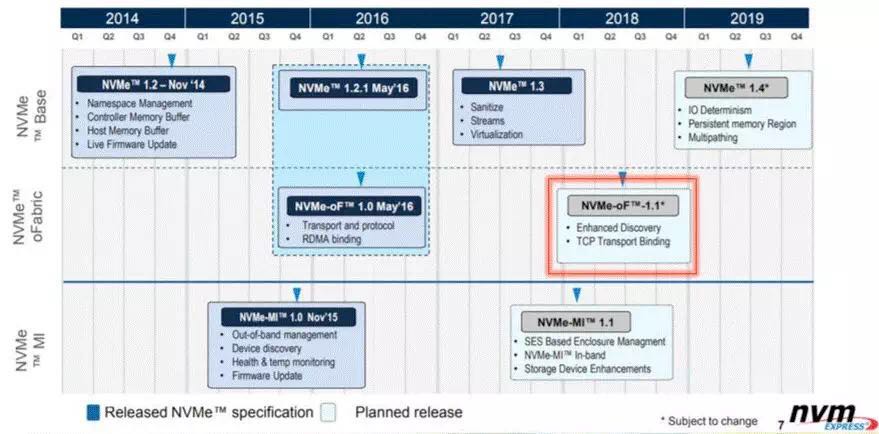
NVMe协议只是针对单机而言,在目前外部存储占据了整个存储市场80%多份额的情况下,发展NVMe over Fabrics就是很自然的事情了。NVMe-oF协议标准同样由NVM Express组织制定,在16年发布了1.0版本。该版本加入了对RDMA Fabric的支持(注:NVMe over FC的标准由T11制定)。而在今年将要发布的1.1版本的标准中,将会加入对TCP的支持,通过将NVMe Verbs封装在TCP中进行传输,并依赖TCP来做流控。其主要的支持厂商有SolarFlare, Cavium和Toshiba。
对于这几种Fabrics,在目前已经采用或将要采用NVMe-oF的系统里,传统的存储厂商倾向于NVMe over FC,譬如NetApp的A系列AFF,IBM的FlashSystem 9100等。其好处是可以重复利用数据中心里现有的一些基础设施架构,在一套环境中支持两种协议(NVMe over FC和FCP),便于迁移过渡。而一些新兴的NVMe-oF创业公司,则采用over RDMA方案的居多,譬如E8 Storage, Excellero等,均采用的是RoCE,获取更低的IO时延。
下面看看NVMe新加入或是将要加入的一些特性能带来哪些好处。
Streams
1.3版标准里加入的Directives功能,在每个NVMe命令里增加了2个字段,DTYPE和DSPEC,分别表示Directive的类型和参数,目前还只是给Streams功能用。那Streams功能有啥用呢?
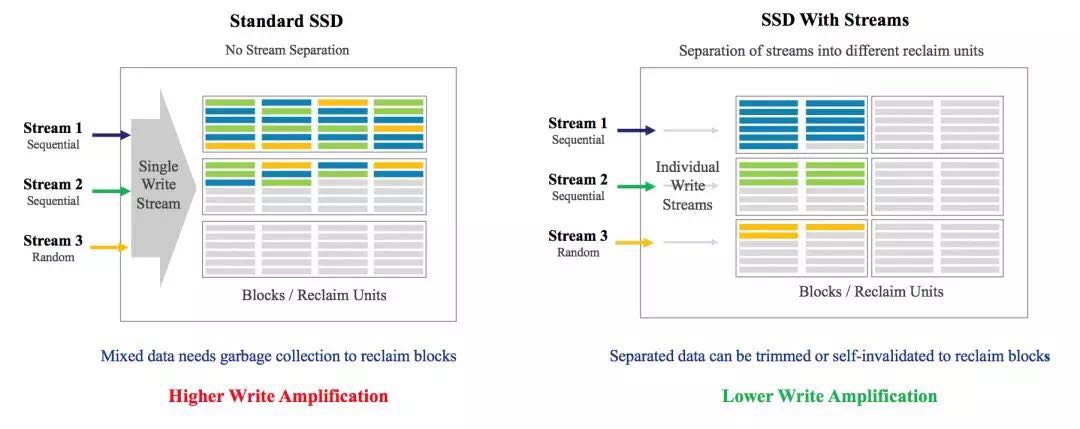
从下图可以看出,在目前普通的SSD上,当应用有多个流往SSD上写的时候,在SSD内部只有一个流,FTL会把应用的多个流上的数据合并写到Flash上。多个流的数据没有规律的随机分布在不同的Flash单元中,而不管他们的冷热度,负载类型等。这样带来的问题是会加大GC的开销,增大WAF,降低寿命,同时也意味着更低的性能。如果SSD能支持多个流的话,应用可以根据数据冷热度,负载类型分别写到不同分组的Flash单元的话,FTL的GC工作会轻松的多。据华为介绍,在他们的系统上应用了这个功能后,SSD盘的耐用度提高了23%,性能提升了21%。
IO Determinism
IO Determinism的提出主要是为了解决SSD在Multi-Tenants共享使用时相互影响的问题。特别是应用一般对读比较敏感,如果这个时候有Burst Write,读应用的Tail Latency就会变得很大,无法保障业务的正常运行。另一方面,SSD内部的一些后台操作也会影响应用时延,譬如垃圾回收,磨损均衡,Block擦除,ECC校验等。为了让应用获得一致性的时延,IO Determinism采用的方法是在NVM里引入了Set的概念,它是SSD内部硬件资源的集合的一个抽象。每个Set都有自己单独的NAND块和Channels,写操作和后台操作也是独立的,做到物理隔离,这样不同Sets之间就不会相互影响了。
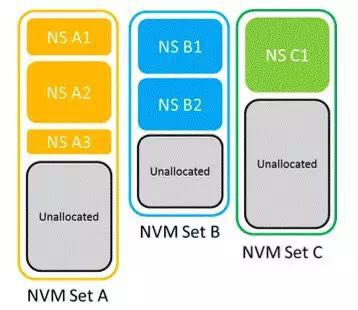
这项工作的标准化工作还在进行中,包括来自Facebook, Seagate, Toshiba的一些工程师在做一些原型方面的工作。Facebook的工作显示在相同类型负载的情况下,划分不同Sets对于读Tail Latency能带来8倍的提升,写Tail Latency也可以带来3倍提升。而在读的时候有其他写或读写混合的场景,划分成Sets可以带来10倍的读Tail Latency提升。
CMB & PMR
CMB (Controller Memory Buffer)早在14年底就进入了NVMe 1.2版的标准之中了。目前已经有多个厂商对其进行了支持,包括Intel, Everspin, Eideticom等,Samsung, Toshiba, WDC等马上也会跟进。其实际上是一个PCIe的BAR,可以映射到主机内存中,这样将NVMe的Queues和DMA Buffers放到CMB中的话,就不需要额外的数据拷贝到主机内存中了。来自Eideticom的工程师将该功能实现到了Linux内核和SPDK里,在NVMe-oF的场景下RDMA NIC可以直接将数据传输到NVMe SSD里,可以降低时延和CPU的消耗。
PMR (Persistent Memory Regions)则可以理解为是CMB的可持久化版本,在盘掉电或者重置的时候上面的数据内容不会丢失。其用途将会比CMB更广泛。目前其在明年1.4版本的标准规划当中。当然,要等到SSD厂商真正的支持这个功能,可能需要更长的时间了。
Open Channel
Open Channel SSD将其内部的一些逻辑展现给上层的应用和OS,允许他们通过一些接口来控制SSD内部的动作,譬如何时做GC,数据如何存放,SSD内部如何调度等。其目的也是为了减少SSD的WAF,降低应用并发访问的时延等。
有趣的是,Open Channel的标准并不统一。有个lightnvm.io的网站开发了一套标准,目前已经发展到2.0版本,一些厂商使用的是这个标准,譬如CNETLABS。Linux 4.4内核里的lightnvm子系统就是根据这个标准实现的,在4.11之后的内核里,还添加了对用户太Liblightnvm库的支持。
与此同时,一些其他的厂商也在发展自己的标准。譬如阿里巴巴跟宝存科技联合开发的Venice平台就使用的是自己的规格标准,据称是业界第一套OCS平台,并已经在生产环境中使用。宝存科技的数据显示在使用了这套平台后,高优先级IO的时延可以降低90%,MariaDB原子写操作的TPS提高了50%。
还有一些厂商针对Key Value型的应用提供了专用的接口,将KV逻辑实现在SSD里,这样应用直接对接到盘上,而毋需经过用户态的KV DB和文件系统等。去年的SDC上三星就展示了一个KV SSD的原型。这次会议上宝存科技也展示了一个跟百度联合开发的KV-SSD,8K的Get操作性能提升了780%,Put操作提升了1500%。
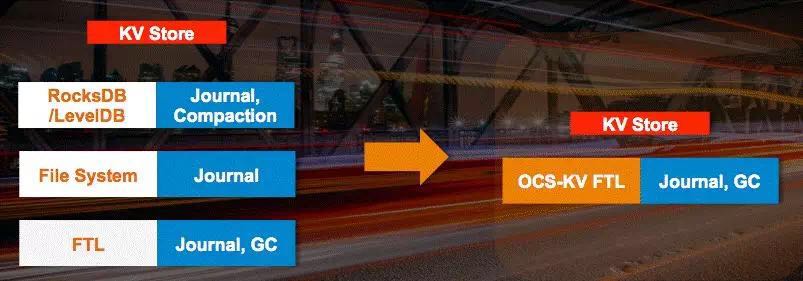
由此可见,各厂商对于Open Channel的态度不一,没有形成一套统一的标准。同时,由于应用需要感知到SSD内部的很多逻辑,增加了其复杂性。因此,Open Channel的未来到底如何发展,还是一个未知数。
「Computational Storage」
这次会议诞生了一个新名词:Computational Storage,并为它开了一个专题来分享讨论。这个领域目前的领导者是两家创业公司ScaleFlux和NGD Systems,其中ScaleFlux来自中国。

ScaleFlux在其CSS 1000系列的NVMe SSD中安装了Xilinx的FPGA,其计算引擎可以用于GZIP压缩,纠删码,KV,AES加密,以及SHA认证等各种通用计算,特别适用于数据库、大数据分析、KV存储等业务类型,并正在将其应用扩展到内容交付、搜索、CDN、人工智能和基因工程等领域。据称使用CSS 1000系列进行计算相对于使用CPU进行计算可以提高5-100倍的速度,其中GZIP压缩速度最高可以提升13倍,模糊检索速度最高可以提升100倍之多。
NGD Systems则在他们的Catalina-2系列的SSD中使用ARM处理器来进行计算,并主打高容量盘,适用于超大规模计算,机器学习,嵌入式人工智能,IoT等领域。其内部的计算单元以C/C++库的形式提供API和CLI供应用调用。